
Creating the world’s best model for Scandinavian languagesCreating the world’s best model for Scandinavian languages
Creating the world’s best model for Scandinavian languages
Creating the world’s best model for Scandinavian languages
Competing at the frontier of AI.
Published Jun 25, 2025

0%
Creating the world’s best model for Scandinavian languages
Creating the world’s best model for Scandinavian languages
Published Jun 25, 2025
See full benchmark
Embedding models are used to translate text into numerical representations and are key components in most modern, generative AI applications. And at The Tech Collective (TTC), we have developed what is right now the world’s best embedding model for Danish, Swedish, and Norwegian.
This embedding model can surpass the performance of leading models from companies like OpenAI, Microsoft, and Salesforce simply because it has been trained specifically on hundreds of thousands of sentences in Scandinavian languages. We have released this model as open source, making it accessible for everyone to use and benefit from. We named it TTC-L2V-2 and you can find it here.
Why use our model? Say for instance that your organisation is developing a chatbot that requires detailed knowledge about your organisation or you are applying AI to organise and extract information from large volumes of existing documents. If so, our model can help you achieve much better results – particularly if the content is written in Danish, Swedish, or Norwegian.
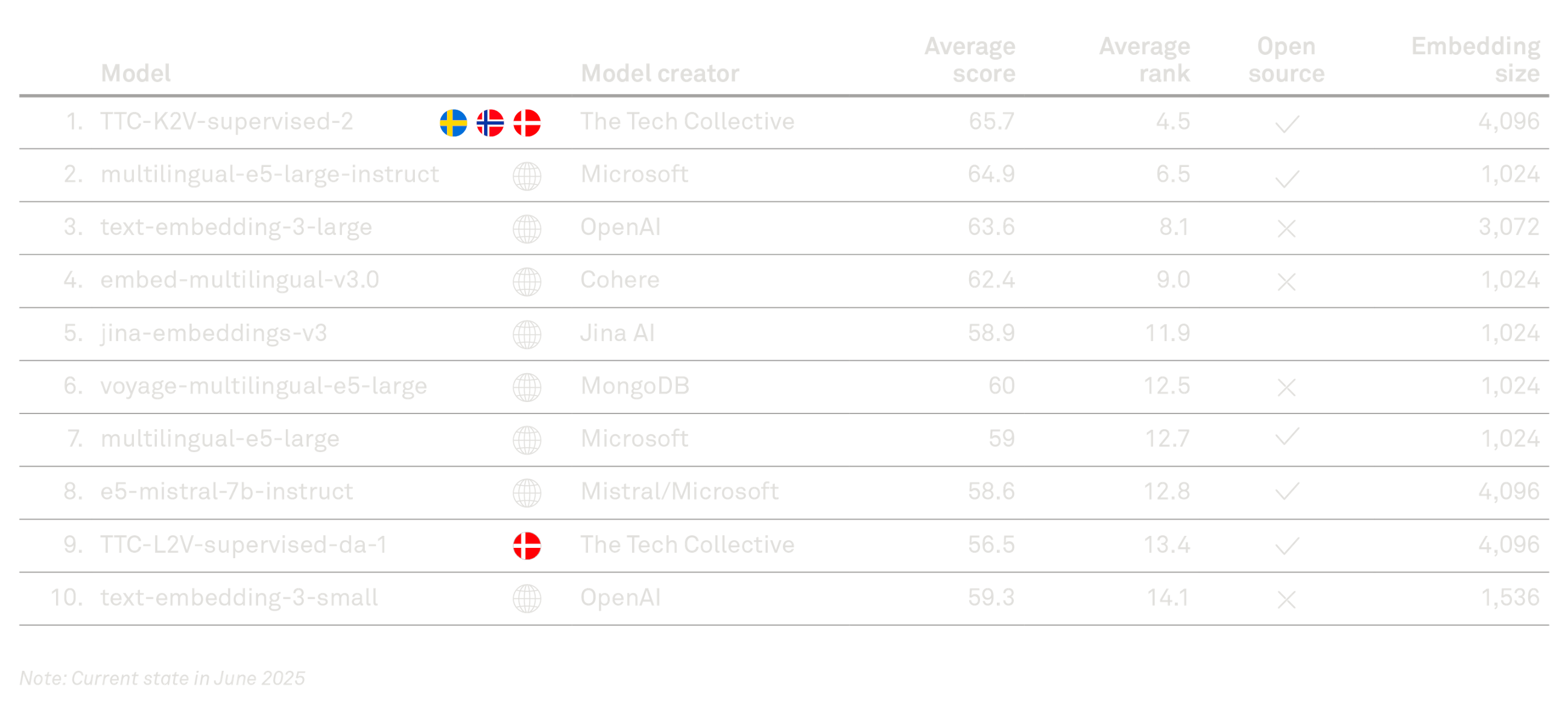
The model has been evaluated by Aarhus University, which hosts the Scandinavian Embedding Benchmark – a comprehensive test involving more than 30 language-specific tasks designed to assess how well models understand Scandinavian languages. As of the publication date, our new embedding model ranks #1 for Danish, Swedish, and Norwegian.
How can this model help enhance Scandinavian AI solutions?
Embedding models are used to create numerical representations of text. This allows us to ask questions like: “How similar are two pieces of text?” or “Which documents are most relevant for this context?”. The most common use case is to enable chatbots to retrieve relevant information to answer user queries, like searching internal documents in a business to provide business-specific answers.
A good embedding model can do this even when documents vary widely in length or use different wording to express the same ideas. A strong embedding model reduces complexity and shifts responsibility away from the user by enabling the AI to search intelligently. In contrast, a poor embedding model may retrieve irrelevant information, leading the AI to respond based on the wrong context – potentially resulting in dangerously inaccurate answers.
If you are curious about the inner workings of retrieval-augmented generation (RAG), you can explore our article on the subject.
Tailoring the model to your organisation
Although our model ranks first on the benchmark, there is still room to enhance its performance by training it further on your organisation’s data. General embedding models are trained on broad datasets, but if your organisation operates in specialised industries like pharma or finance, fine-tuning with your own data can drive substantial improvements – and we can support you throughout that process. Even with limited data, we can apply advanced techniques to synthesise a suitable dataset for fine-tuning, building on the strong foundation already in place.
It is also important to acknowledge that while embeddings are central to a high-performing chatbot, other factors – such as intelligent document processing, query augmentation, and retrieval techniques – play a significant role in overall performance.
For the technically curious: How we trained the model
We did not build this model from scratch; instead, we leveraged an existing open-source language model from Meta’s Llama family. This allowed us to benefit from the substantial resources already invested in training it to understand language, and then apply additional, targeted training in Danish, Swedish, and Norwegian.
One of the main challenges we faced early on was the lack of suitable Scandinavian text data for training embedding models. To address this, our first step was to collaborate with DDSC and NVIDIA to generate synthetic data using another language model. For example, we developed a programme that iterates through Danish Wikipedia articles, using a language model to generate potential questions and answers for each article – producing thousands of ‘question–context–answer’ sets. We also generated fully synthetic data programmatically by prompting a large generative model to create training samples from scratch. The result was the largest Scandinavian dataset to date, comprising approximately one million samples, which we released publicly via the Danish Data Science platform.
Following the creation of the dataset, the model underwent multiple adjustments and training iterations to improve its ability to generate meaningful numerical representations of Scandinavian texts – optimising it for tasks such as retrieval, question answering, and sentiment analysis. Fine-tuning on this dataset not only improved performance on the training data itself but also enhanced the model’s general ability to produce useful embeddings for related tasks.
For a detailed walkthrough of our training process, see our article “‘How to train top 5 Nordic embedding model”, which outlines the steps used to train the earlier version of our model that reached a #5 ranking. We followed the same recipe for the latest version – with the key difference being access to a newly generated, much larger dataset. And that boost helped propel the new model to the #1 spot.
We are always eager to discuss how tailored AI solutions and specialised models can enhance AI performance in your organisation. Do not hesitate to get in touch for an informal conversation about potential opportunities.
Get in touch

Embedding benchmark
Want to learn more?
Read more about our embedding model for the Scandinavian languages and the Scandinavian Embedding Benchmark.
