
How to train a top 5 Nordic AI modelHow to train a top 5 Nordic AI model
How to train a top 5 Nordic AI model
How to train a top 5 Nordic AI model
Here’s how we achieved a top 5 placement for a Scandinavian language embedding model with limited resources.
Published Feb 28, 2025

0%
How to train a top 5 Nordic AI model
How to train a top 5 Nordic AI model
Published Feb 28, 2025
See full benchmark
At The Tech Collective, powered by Implement Consulting Group, we’ve recently achieved a top 5 ranking embedding model for Scandinavian languages by fine-tuning an existing large language model (LLM).
But what does such a journey look like, and how can it help demonstrate the power and accessibility of tailored AI solutions for businesses?
Achieving top-tier performance
Our aim was to explore the creation of an embedding model, a critical component in modern natural language processing (NLP) and artificial intelligence development, specifically tailored to Scandinavian languages. What began as a research endeavour culminated in the development of a model that not only performed exceptionally well but also secured a top 5 position in benchmarks for Danish and Norwegian, along with an impressive second-place ranking for Swedish.
This achievement is noteworthy for several reasons, and a story we’re excited to share. Firstly, it demonstrates that organisations like ours, which are not dedicated AI research labs, can still develop high-performing AI models. Secondly, it highlights the effectiveness of fine-tuning existing large language models (LLMs) to achieve specialised tasks with limited computational resources. Finally, and perhaps most importantly for businesses, it underscores the accessibility of cutting-edge AI techniques, enabling even small to medium enterprises (SMEs) to leverage sophisticated NLP solutions.
Understanding embedding models and LLM-to-vec
Imagine trying to explain the concept of "banana" to a computer. Computers don't see images or taste fruit like we do; they understand numbers. So, how do we bridge this gap and teach a computer what "banana" means, especially when it comes to understanding text about apples? This is where embedding models come in.
Think of embedding models as smart dictionaries for computers. Instead of just providing definitions, these models translate words, phrases, and even entire documents into a format that computers can understand – long lists of numbers, called vectors. These vectors are special because they capture the meaning of the text. Words with similar meanings, like "banana" and "fruit," will have vectors that are close to each other, while words with different meanings, like "banana" and "car," will have vectors that are far apart.
This numerical representation is incredibly powerful. It allows computers to perform amazing tasks with language, such as:
Understand search queries
When you search for "recipes with bananas," an embedding model helps the computer understand the meaning of your query and find documents that are semantically related, even if they don't match the exact words "recipes with bananas."
Analyse document similarity
Want to find documents that are similar in content? Embedding models can compare the vectors of different documents and tell you how closely related they are by calculating the distance between them.
Power advanced AI
Embedding models are fundamental building blocks for more complex AI systems, including large language models (LLMs) that power chatbots and other advanced applications.
Traditionally, embedding models were trained using specific architectures, often encoder-based models like BERT. However, the rise of powerful decoder-based LLMs, such as those powering chatbots, has presented a new opportunity. As it turns out, the core engine of both encoder and decoder models is remarkably similar; they are based on transformer networks and attention mechanisms but tweaked and trained in different ways.
A novel approach called LLM-to-Vec leverages the inherent language understanding capabilities already embedded within these LLMs. Instead of training a new embedding model from scratch, LLM-to-Vec allows us to repurpose an existing LLM, fine-tuning it to excel specifically at generating high-quality embeddings.
Our fine-tuning journey
To create our top-performing Scandinavian embedding model, we set out to fine-tune an existing large language model (LLM). Think of fine-tuning as being a bit like specialised education. A pre-trained LLM is like a student with high school knowledge – basic language understanding. Fine-tuning is our "university degree," which focuses on learning a specific task: creating embeddings. This is efficient and resource-light compared to training from scratch.
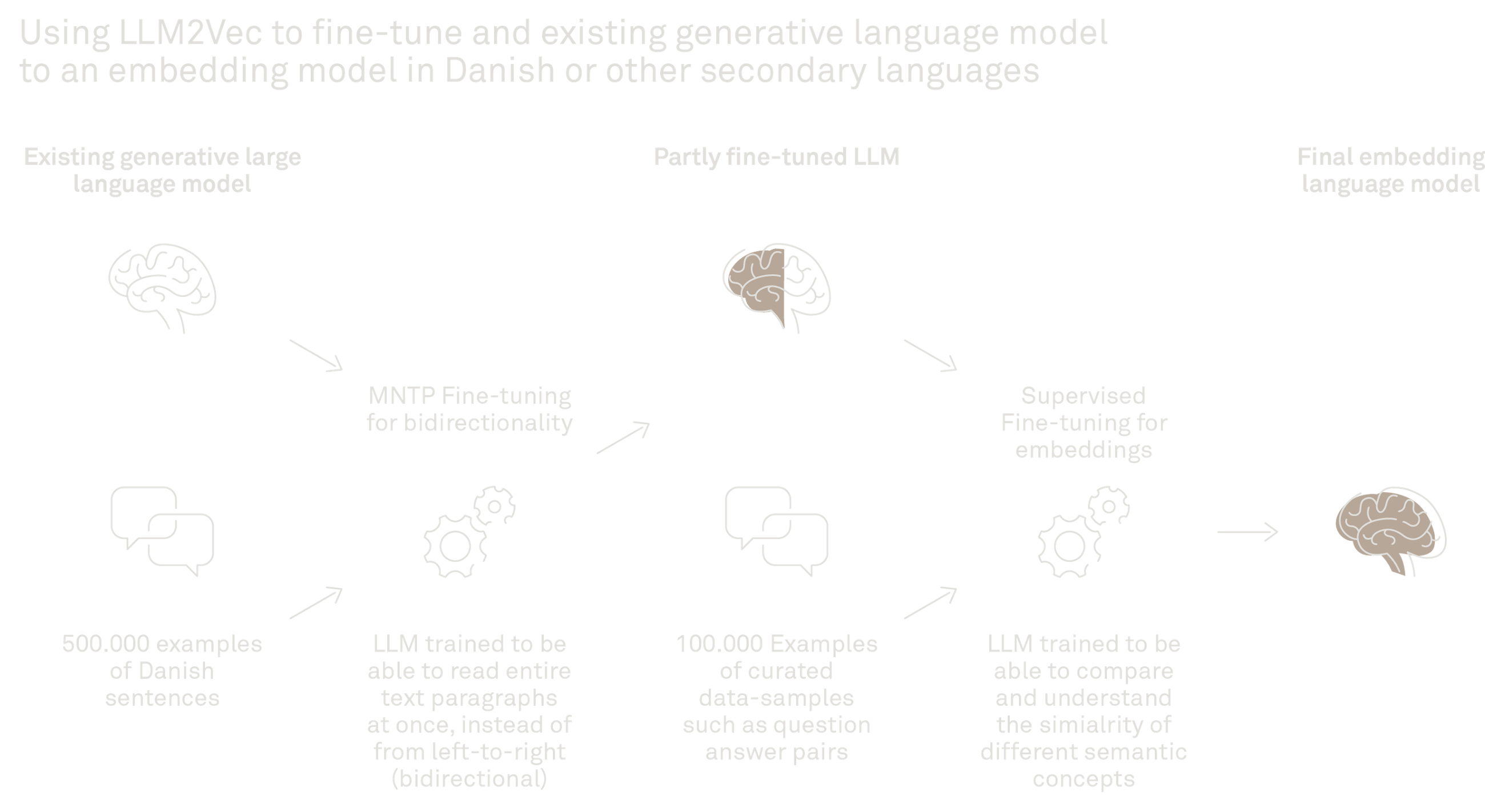
Our fine-tuning involved three key steps
Step 1: Bidirectional attention – seeing the whole picture
We modified the LLM's attention mechanism. Standard LLMs use unidirectional attention, focusing only on preceding words. For embeddings, we need bidirectional attention to understand the entire text at once. We adapted the model to consider the full context of sentences and documents when creating embeddings. This enables the model to read the entire paragraph for context when generating a numerical representation.
Step 2: Masked next token prediction – language exercise
We used masked next token prediction, MNTP. This is like a "fill-in-the-blanks" exercise. We trained the model to predict missing words in sentences, forcing it to deeply understand Scandinavian languages bidirectionally. In doing so, the model learns it can now look at the entire sentence to create the best possible text representations and sharpens its understanding of Scandinavian language.
Step 3: Embedding-specific fine-tuning – optimising for relevance
The final step: embedding-specific fine-tuning. We trained the model to create embeddings that reflect semantic similarity. This step teaches the model to be good at the kind of tasks we often use embeddings for, like similarity search, question-answer matching etc. Amongst other things, we used examples of questions and the related documents which contain the answer to train the model to embed matching question-answer pairs close to each other in the vector space, while positioning unrelated questions and texts further apart.
A noteworthy point to make here is that the question-answer pairs were mostly created synthetically using AI. By using the Danish Wikipedia and an open-source Google Gemma 27B on the same GPU, the questions needed for training were automatically generated based on the Wikipedia pages.1 This approach opens new opportunities for various business domains, like generating training data from contracts, SOPs, work instructions, or other business documentation. We used as few as 100,000 examples to do our training, and we expect volumes like this can be generated with 20,000-30,000 documents.
These three steps transform a general LLM into a specialised embedding model. It’s like vocational training, focusing language skills on creating comparable text representations. Aside from not requiring a ton of data, the computational resources needed for training are also manageable. A single A100 GPU completed training in just 24 hours – a fraction of the resources for training LLMs from scratch. This highlights the accessibility of fine-tuning for achieving specialised AI.
[1] The dataset was generated and open-sourced by DDSA, The Danish Data Science Community
Business implications and accessibility for you
While generic, off-the-shelf embedding models serve as a valuable starting point. Businesses seeking optimal performance – especially for specialised language needs like Scandinavian languages or industry-specific jargon – should consider the power of fine-tuning. This approach offers a pathway to create state-of-the-art AI solutions that can significantly enhance various business applications, from improved search functions to more intelligent document processing and analysis.
The future of tailored AI is well within reach
Our journey of creating a top-performing Scandinavian embedding model underscores a crucial trend in AI: the increasing accessibility and customisability of powerful technologies. The LLM-to-Vec approach, combined with fine-tuning techniques, now empowers organisations to move beyond generic AI solutions and develop tailored models that precisely address their unique needs.
At The Tech Collective, we are currently exploring further advancements in this area, training even more powerful models to push the boundaries of our own and our clients’ performance. Our initial success with the Scandinavian embedding model serves as a compelling proof of concept, demonstrating that with strategic fine-tuning and readily available resources, businesses like yours can (somewhat) easily leverage state-of-the-art AI techniques like these.
As AI continues to evolve, the ability to customise and adapt existing models will become increasingly critical, paving the way for a future where powerful AI is not only accessible but also deeply integrated and tailored to the specific needs of every organisation.

Embedding Benchmark
Want to learn more?
Our score was achieved on the Scandinavian Embedding Benchmark, an open leaderboard maintained by the team at Aarhus University’s Center for Humanities Computing. See the full benchmark and documentation.