
Teaching computers to seeTeaching computers to see
Teaching computers to see
Teaching computers to see
What computer vision can do – and why it matters.
Published Oct 15, 2025
0%
Teaching computers to see
Teaching computers to see
Published Oct 15, 2025

Michel Poesze

Johannes Reiche
Frederik Schöller
Since ChatGPT burst onto the scene, most people have seen how AI can understand and generate text. Fewer people know that the same leap is currently happening in vision: computers can now make sense of images and video, effectively giving software a pair of “eyes” when connected to a camera.
This capability, called computer vision, powers practical applications across manufacturing, logistics, retail, healthcare, construction, agriculture, and more. These modern vision systems are driven by large “foundation models” trained on vast amounts of image data, similar in spirit to large language models. That means faster deployment, more accurate results, and the ability to learn new tasks with less labelled data.
In this article, we explain computer vision in plain language, outline the key tasks it can perform, show where it delivers real value, and provide practical guidance for moving from pilot projects to full-scale production – safely and responsibly.
What is computer vision? And why now?
Computer vision is software that looks at photos or video, and answers questions about what is there. Sometimes the question is simple, “Is there a box?”, and sometimes it is more involved, “How many boxes are on the conveyor, and does any of the boxes contain a defect?” Vision can run on live video, recorded footage, or still images.
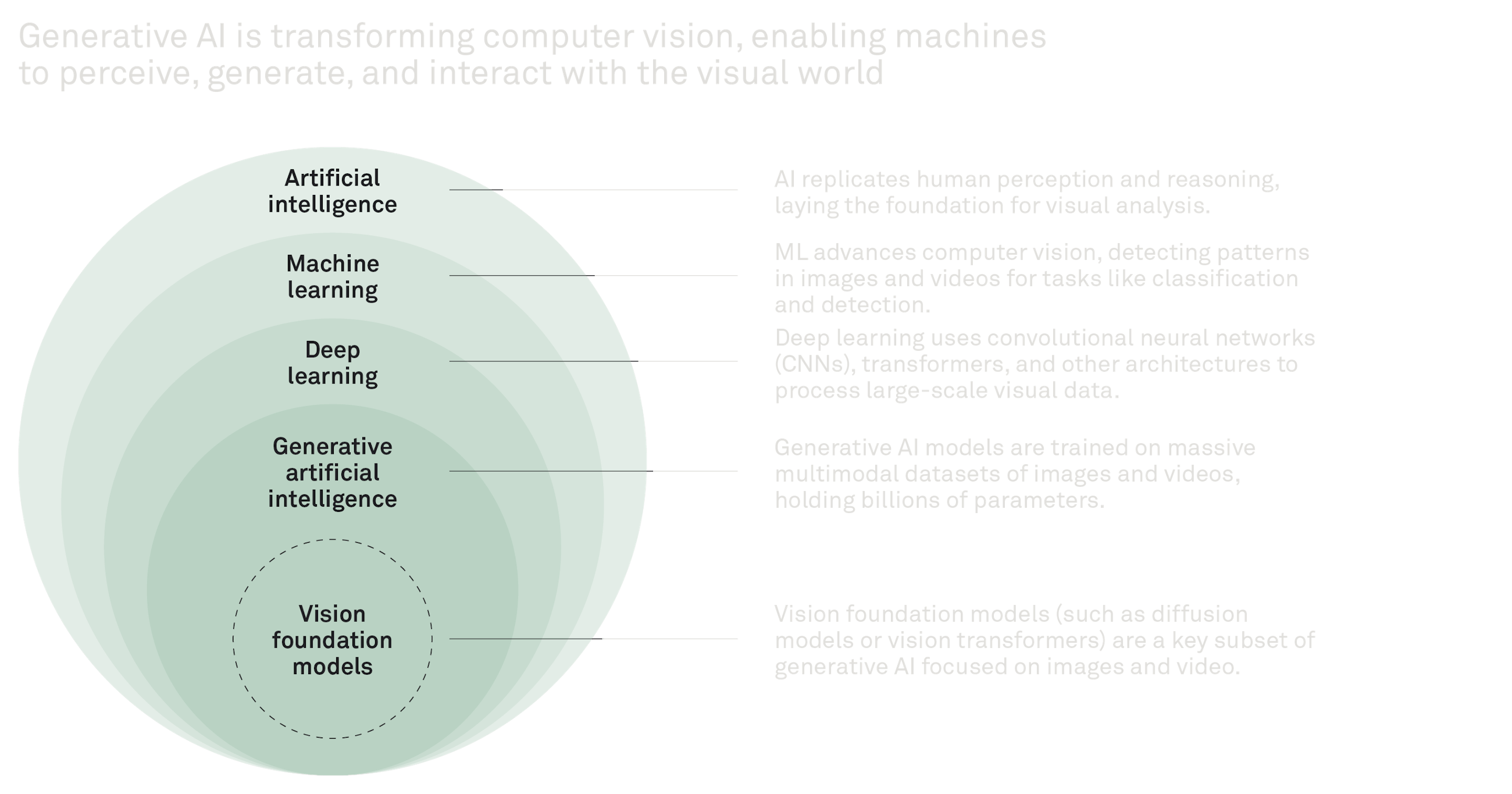
Computer vision has been around for decades, but what makes it powerful today is how recent advances have made it practical for real-world industrial use:
- Better algorithms: Vision foundation models (for example, CLIP for image-text alignment and self-supervised models like DINO) give computers a strong “visual prior” that quickly allows us to teach the models to understand a new problem.
- Cheaper, better hardware: High-quality cameras are everywhere. From the smartphone in your pocket, CCTV, industrial cameras, and drones. This combined with edge devices that can run real-time AI models makes computer vision more accessible than ever.
What eyes like these can see – and make possible
Most computer vision systems are built around a handful of core skills. The first is classification, which determines what an image shows at a high level, such as “Type A vessel” versus “Type B,” or “defect” versus “no defect.” When you need to locate objects and count them, detection and tracking step in, identifying each item and following it over time to measure flow on a production line or movement in a warehouse. If there is text in the scene, OCR (optical character recognition) reads it – from lot and batch codes to meter readings and price labels.
For precise inspection, segmentation outlines the exact shape of an object down to the pixel, helping detect surface defects, cell boundaries, or lane markings on a road. When space matters, 3D reconstruction and SLAM build a digital model from ordinary video while tracking the camera’s position within it – useful for digital twins, as-built vs. as-designed checks, and autonomous navigation. And when movement or posture is key, pose estimation tracks points on the human body (or articulated machines) to assess ergonomics, safety, or performance.
In practice, these skills are often combined. A packaging line might use detection plus OCR to count items and verify labels. A construction team might pair 3D reconstruction with detection to compare site progress against plans. A warehouse may mix tracking and pose estimation to reduce risky lifts while improving people flow.
The state of computer vision – from AlexNet to everything
It has been ten years since deep convolutional networks such as AlexNet first outperformed handcrafted pipelines on ImageNet. This breakthrough opened the door to industrial quality control and autonomous driving.
In 2020, Vision Transformers (ViTs) arrived, replacing local convolutional filters with global self-attention. When pre-trained on massive collections of unlabelled images, ViTs learn both fine-grained detail and global context, matching or surpassing CNN accuracy while adapting to new tasks with minimal data.
Today’s foundation models – CLIP, DINO, Segment Anything, Stable Diffusion – share one trait: they learn generic visual concepts that can be prompted, queried, or fine-tuned for almost any downstream use case. For your business, that means:
- Less labelling: One or two hundred high quality annotated images are often enough to reach production accuracy.
- Faster iteration: New inspections or SKU classes can go live in days, not quarters.
- Multimodal workflows: You can ask a vision model questions in plain language, “Show me every missing weld from yesterday’s night shift,” and receive a video clip plus counts.
Pixels to profit – Six areas where vision pays
We now know what vision can do and why the timing is right. The next question is simple: where does it show up in the P&L today? The examples that follow are production deployments, not lab demos. They translate pixels into throughput, yield, safety, and working‑capital gains across core industries.
As such, these examples can be seen as patterns you can reuse. Anywhere people currently inspect, count, or verify, computer vision can help reduce latency and variability – provided detections trigger action within the system of work. Simply put, when a model can halt a robot, quarantine a vial, issue a restock, or reconcile inventory automatically, images become outcomes.
The six areas where vision pays
Healthcare and pharma
- AI triages and analyses CT lung scans, increasing radiologist throughput while maintaining quality.1
- Automated vial/syringe inspection on fill-finish lines eliminate microdefects, cutting scrap and avoiding recalls.2
Retail and e commerce
- Checkout-free formats reduce average transaction times from several minutes to near zero, improving conversion rates and the customer experience.3
- Overhead vision flags shelf gaps in real time; restock alerts prevent lost sales from out-of-stocks.4
Manufacturing
- 100% spot-weld inspection at Audi analyses ~1.5 million welds per shift, reducing rework and warranty exposure.5
- Vision guided robots handle bin picking and screw driving with 24/7 consistency, stabilising cycle times and reducing ergonomic risk.6
Agriculture
- John Deere See & Spray automated weeds detection in fields reduces herbicide use by up to 62% while maintaining or increasing yield.7
- Drone imagery detects early crop stress, enabling targeted irrigation and fertiliser to boost input ROI.8
Logistics & supply chain
- Vision sorters double parcel throughput on existing conveyors while trimming labour costs.9
- Autonomous forklifts and inventory drones maintain up-to-date stock counts, enabling higher service levels while reducing working capital.10
Construction
- AI monitors PPE compliance and unsafe proximity events, contributing to fewer recordable incidents on compliant sites.11
Your 2025 computer vision playbook
Turning those outcomes into your outcomes is a delivery challenge, not an algorithm hunt. Treat computer vision as an operations programme anchored to KPIs the business already trusts, and design it around real-world constraints: your cameras and lighting, your networks, and your privacy rules.
Foundation models and edge compute mean you can move from camera to KPI in weeks, not quarters. Start small and at the edge, fine-tune rather than reinvent, and measure model quality and business impact side by side. Do the governance work up front – legal, security, and works councils – so a successful pilot can scale without rework. After 90 days, the goal is one live use case with a signed-off ROI and a funded backlog to expand.
Audit the eyeballs and define value
- Walk the floor and capture every task where people look, count, measure, or verify. For each, estimate time spent, error rate and risk, and note the systems of record and downstream impacts if something is missing. Use existing cameras, lighting, networks, privacy constraints, and retention rules so the pilot runs in the real world, not the lab.
Prioritise by ROI
- Tie each candidate to a hard KPI the business already tracks – scrap rate, shrink, throughput, yield, safety, DSO. Assess value versus effort, pick quick wins, and secure an executive sponsor and budget so that access and decisions do not become bottlenecks.
Run edge‑first pilots
- Prove it on one line, one ward, or one store, within a maximum of eight weeks. Use production cameras, lighting, and compute, and deploy at the edge to meet latency and privacy constraints. Define pass/fail criteria upfront (e.g., >20 % KPI lift or <2 % false alarms) and a rollback plan to enable a clean go/no‑go decision.
Fine‑tune, do not reinvent
- Start from a proven foundation model and adapt it with hundreds, not hundreds of thousands, of labelled frames. Use active learning to harvest hard examples, add synthetic data where appropriate, and apply lightweight adapters or distillation to fit onto small edge devices.
Measure and iterate
- Instrument both sides of the equation: model performance (precision/recall, drift, uptime) and business impact (scrap avoided, minutes saved, compliance rates) on a single dashboard. Keep humans in the loop for edge cases and schedule periodic retraining and threshold calibration to maintain accuracy.
Build trust early
- Engage legal, security, and works councils from day one; run DPIAs where required; minimise data capture and anonymise by default. Document data lineage, access, and retention; align with the EU AI Act and NIST RMF; publish user notices and training. Prove safety and reliability before scaling to avoid regulatory surprises.
Eyes on the future
By 2026, computer vision will feel less like a patchwork of point solutions and more like a single, omnilingual colleague. Foundation-scale “PerceptionGPT” models will natively juggle pixels, LiDAR, radar, and even text, giving every camera a plug-and-play “one model, any modality” brain. Thanks to efficiency breakthroughs such as Token-Merging Vision Transformers and Flash-Attention v3, the same intelligence will run locally and fast – halving latency, cutting VRAM use by 60%, and fitting into sub-2-watt AR glasses without melting the wearer’s ears.
Regulation will tighten in parallel: the EU AI Act is set to require auditable lineage for every training frame, likely spawning an entire data-provenance sector to track who captured what, where, and when.
And because these systems will finally “speak human”, a plant manager will be able to ask, “Show me every conveyor jam from yesterday,” and receive clipped highlights and anomaly stats instantly – no SQL, no Python, just answers. In short, vision tech is about to become native, portable, accountable, and conversational all at once.
Sources:
1. Cheo, H. M. (2025). A systematic review of AI performance in lung cancer screening. Healthcare, 13(3), 1510. https://pmc.ncbi.nlm.nih.gov/articles/PMC12250385/
2. Nosrati, R., Emaminejad, N., Ganapathi, S., et al. (2025). Advancing industrial inspection with an automated computer vision solution for orthopedic surgical tray inspection. Scientific Reports, 15, 7867. https://www.nature.com/articles/s41598-025-88974-6
3. Şimşek, H. (2025, August 12). Top 4 checkout-free systems: Pros, cons & case studies. AIMultiple. https://research.aimultiple.com/checkout-free/
4. Pietrini, R., et al. (2024). A deep learning-based system for shelf visual monitoring. Computers in Industry. https://www.sciencedirect.com/science/article/pii/S0957417424015021
5. Audi AG. (2023). ALP winner 2023: Digital use case. Automotive Lean Production. https://www.automotive-lean-production.de/en/browse-winners/alp-winner-2023-digital-use-case
6. Sága, M., et al. (2020). Performance analysis and development of robotized screwing application with integrated vision system. Journal of Intelligent Manufacturing, 31(5), 1239–1253. https://journals.sagepub.com/doi/full/10.1177/172988142092399
7. Su, J., et al. (2024). Design of a robot system for reorienting and assembling irregular parts using machine vision. Journal of Intelligent Manufacturing, 35(3), 789–803. https://www.cambridge.org/core/blog/2024/11/21/machine-vision-technology-shows-promise-to-reduce-herbicide-use/
8. Dodde, M. (2024, November 21). Machine-vision technology shows promise to reduce herbicide use. Cambridge University Press. https://www.cambridge.org/core/blog/2024/11/21/machine-vision-technology-shows-promise-to-reduce-herbicide-use/
9. Bhakta, A., et al. (2025). Development of a robust deep learning model for weed classification across diverse turfgrass regimes. Weed Science, 73(2), 123–135. https://www.nature.com/articles/s41598-024-66941-x
10. Raj, H. K., & Hariharan, V. (2024). Autonomous forklift system using robot control system. International Journal of Progressive Research in Engineering Management and Science (IJPREMS), 4(9), 739-745. https://www.ijprems.com/uploadedfiles/paper/issue_9_september_2024/36045/final/fin_ijprems1727176843.pdf
11. Aalborg University. (2024). EC32024_307.pdf. https://vbn.aau.dk/ws/portalfiles/portal/752029769/EC32024_307.pdf